Introduction
In former times , relational databases grew increasingly dominant. It delivers rich indexes to make any query efficient. Table joins, which are used for operations that pull together separate records into one. And transactions, which meant a combination of reads and especially writes across the database. But, they need to happen together. Strict guarantees were engineered in to prevent surprises. Relational databases designed around the assumption of running on a single machine lacks something that became essential with the advent of the internet. They were painfully difficult to scale out. The volume of data that can be created by millions or billions of networked humans and devices is more than any single server can handle. When the workload grows so heavy that no single computer can bear the the load. When the most expensive hardware on the market will be brought to its knees by the weight of an application. The only path is to move forward from a single database server to a cluster of database nodes working in concert. For a legacy SQL database designed to run on a single server, this was a painful process. But, for those who needed scale, there were other options.
NoSQL had arrived on scene. Google Bigtable, HDFS, Cassandra and Mongo are a few examples. These NoSQL databases were built to scale out easily and to tolerate node failures with minimal disruption. But, they came with compromises and functionality. Typically, a lack of joins and transactions or limited indexes, shortcomings. The developers had to constantly engineer their way around. Scale became cheap. But, relational guarantees didn't come with it.But none of these were architected from the ground up to deliver what we might call distributed SQL.
And that's where Cockroach DB comes in.
Cockroach DB as Distributed SQL
Distributed SQL, Which is, neither a legacy SQL database like my SQL, nor a NoSQL database, like Cassandra, but something that offers the rich functionality of a relational database as well as the scalability and resiliency of NoSQL. The database need to have the following features exactly to qualify as distributed SQL,
- First, it's got to be distributed, which is to say it has to scale and do so seamlessly. This is where legacy SQL databases really fell short. Now, that's not to say they can't scale, one can shard up Postgres database and people do, but it's a lot of extra work and anyone doing it has to be careful because it comes with compromises.
- Next up is consistency.And in this context, we mean that readers always see writes and they see them appear in the same order in which those writes occur.This is an area where NoSQL often runs into issues.
- Resiliency is another area where legacy SQL databases fall short. They've added some resiliency features over the years, but it's not smooth, and it often requires some level of extra designing and or human intervention.
ACID guarantees are important and they're hard enough to implement even on a single machine.When someone says ACID guarantees, it's about four promises,
- First, transaction has to be atomic, meaning that all parts of the transaction happen or none.
- Second, they have to be consistent, which in this context means the transaction has to respect any rules imposed on the database like foreign key constraints, and move from one consistent state to another with no inconsistent states visible to any readers at any time.
- Third, they have to be isolated, meaning that even though the database might be able to parallelize some operations, it can't permit it to look like they're interleaved.
- Finally, they have to be durable. When a transaction is committed, it stays committed even in the face of node failure.
All together, these form a basic set of requirements for distributed SQL.
How Cockroach supports ACID ?
Every transaction in Cockroach DB guarantees ACID semantic spanning arbitrary tables and rows. There are no tunable guarantees. It offers the same strict guarantees at all times, even when data is distributed. This is extremely important since no single node is responsible for all of the data that affects the transaction, and all nodes participating in a transaction must agree on whether or not it should be committed.
ACID in Cockroach
ACID stands for atomicity, consistency, isolation and durability. It is a set of database transaction properties that guarantee validity in the event of failure like system crashes, power failures and other errors.
Atomicity : It means transactions are all or nothing. If any part of a transaction fails, the entire transaction is aborted and the database is left unchanged. If a transaction succeeds, all mutations are applied together. SQL operations never see any partially-written states from transactions.
Consistency : It enforces rules on data. This means that any data written in a transaction will be valid according to all defined rules, including SQL constraints.
Isolation : This property ensures that concurrent transactions, that is multiple transactions that happen at the same time, will leave the database in the same state that it would have been in if the transactions were executed serially, or one after another. This is called serializable isolation. This ensures data correctness by preventing all anomalies allowed by weaker isolation levels. These are things like dirty reads, dirty writes, and other more subtle errors you may encounter in other databases. Cockroach DB always uses serializable isolation, which is the strongest of the four isolation levels defined by the SQL standard. It is a higher level of isolation than what many legacy SQL databases offer and it is stronger than the snapshot isolation level developed later.
Durability : It guarantees that once a transaction is committed, it will remain committed. In Cockroach DB, this means that every acknowledged write has been persistent consistently on a majority of replicas through the raft consensus algorithm. Acknowledged writes will never be rolled back, even in the case of node failure.
All data access in Cockroach DB is transactional, which guarantees data integrity. Since Cockroach DB offers the strictest ACID guarantees by default, the data will always be consistent.
Clusters in Cockroach
We have to understand at a high level how the cluster scales out, which is important to everyone because it has performance implications it will also help to build a conceptual foundation for things to come.
First, let's talk about the ordering of data in CockroachDB. Take a bunch of data and imagine it in a single grand structure, we're going to call the Keyspace. It's an ordered set of key value pairs with the full path to each record in the key part of each entry including where it lives and the primary key of the row. The important thing is that everything we can use to find a record including the primary key are all part of the Keyspace. The rest of the row's columns are typically put into the value part of the KV store and don't affect the ordering. So the key spaces all of this with additional metadata all together in a grand ordered data structure, for a single node cluster the Keyspace is a fairly accurate description of how the data is actually organized by the storage layer.
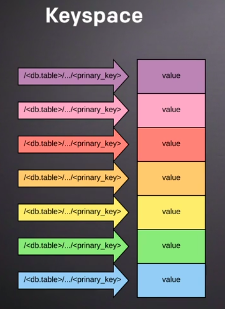
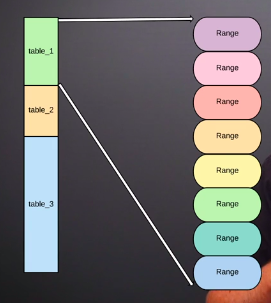
The reason why it's a useful abstraction is because the cluster divides the Keyspace into what we call ranges. When a range grows beyond a certain limit megabytes by default, it gets split into two. The default range size is 512MB from the version v20.1, and 64MB in previous versions. When those grow each gets split again and so on. Splits can also occur for other reasons, but ranges are important because they are the units that CockroachDB replicates and distributes to the nodes of the cluster. Multiple copies of each range called replicas are distributed among the nodes to keep the cluster balanced.
In CockroachDB, the default replication factor is three. Moreover, each replica is always on a different node, they never double up, we can increase the replication factor to larger odd numbers, such as five or seven to increase the resiliency. Higher replication factors do come with cost of having to store update and synchronize more replicas of each range in your cluster. Sometimes that's worth the cost sometimes not.
Know that your replication factor doesn't have to be the same for all of your data. We can set a different replication factor for each database or table if required, or get even more granular provided we own a enterprise license.
RAFT
Raft is an algorithm that allows a distributed set of servers to agree on any values without losing the record of that value, even in the face of node failure. This is where CockroachDB's guarantees come from. CockroachDB uses it to perform all writes. For CockroachDB, each range defines a Raft group. If a cluster has seven ranges, so there will be seven raft groups.
Before we get into the details of Raft, though, CockroachDB has a concept of something called a lease, which it assigns to one of these replicas called the leaseholder. Its job will be to serve reads on its own bypassing Raft but also keeping track of write commits, so it knows not to show writes until they're durable.

The first thing to know about Raft is that replicas are either leaders or followers. Leaders coordinate the distributed write process while followers assist. If a follower doesn't see a heartbeat from a leader, it'll get a randomized time-out, declare itself a candidate, and call for an election. Majority vote makes it a leader. The process takes seconds. In practice, CockroachDB does a good job of keeping the lease with the leader for efficiency. So we'll assume that scenario. Writes are kicked off by the leaseholders which tells the leader to begin the process. When a insert happens. The leader first upends the command to its Raft log, which is an ordered set of commands on disc. The leader then proposes the write to the followers. Each follower will replicate the command on its own Raft log. Even without hitting all the nodes, the write will persist through any single node failure. Consensus has been achieved, but the leader doesn't know that yet. So the follower has to let it know. At this point, the leader knows the Raft command was replicated so it can commit the write and notify the leaseholder to begin showing it to readers. Eventually, that write will go to every replica. The leaseholder ensures that readers only see committed writes, and that replicas arranged together form a Raft group that elects one leader.
Nodes & Gateways
Now we know how the cluster breaks its data down into ranges, replicates and distributes those ranges to the various nodes and uses the Raft protocol to keep cluster data, durable and consistent, Now let's look at how those nodes act together to keep data available in the face of node failure. Consider a three-node cluster, the smallest size for a resilient production deployment and a client connect to the cluster. Which ever node the client connects to is called the gateway and it'll route queries wherever they belong. The client can make any node its gateway just by connecting. Next, note the leaders of the various ranges are not all on the same node. They're distributed roughly equally among the three nodes.
Suppose that a client sends a query asking for rows from two of those ranges. Here's how the query might get answered while three nodes are up. First, the gateway would route the query to the appropriate leaseholders and since it's a read query, they would send the results back to the gateway which would combine them and answer the client's query. The only difference for a write is that there would be a consensus operation started by the leader for each Raft group. But the flow would otherwise be similar with an acknowledgement returned by the leaseholder back to gateway and on to client.
Okay, so what happens when a node goes down? Well, first if a client is connected to that, that client would need to find a new gateway. This problem would be solved by using a load balancer which is crucial in production deployments. More interesting thought is what happens to those ranges in the moments immediately following node failure. Suppose a write comes in just as a node goes down, the leaders on a node is still up, there's no problem. But for a range whose leader went down, there's a short term problem, no leader. That Raft group will hold an election turning a follower into a new leader in a matter of seconds. The lease will be reassigned as well and the gateway will route the write to the new leaseholder. Once it knows that the remaining two nodes have achieved consensus, it'll acknowledge the write back to the gateway. So the clusters able to keep serving writes as well as reads with perhaps a few seconds of latency but only if the query comes in at exactly the wrong time and it touches on a range that's temporarily leaderless. But, we are down to two nodes at this point and until that node comes back up, well the cluster is able to serve reads and writes just fine, it's also in a fragile state. The second node is lost at this point, consensus becomes impossible and the cluster will be unavailable until it's back to at least two nodes. We want it to get back to a resilient state as quickly as we can. When that third node does come back up, it'll rejoin the cluster and assuming it hasn't been too long, its ranges will rejoin their respective Raft groups as followers replicating Raft entries and the cluster will again be in a resilient state.
Up-Replication
Having already seen a three node cluster respond to node failure, we're now going to look at what happens in a larger cluster, where each range is replicated to only a subset of the nodes. This is often done to scale out by the way, distributing ranges with their read and write workloads across more nodes, while keeping the replication factor constant. Let's consider a cluster with seven nodes, still with a replication factor of three for every range. The replicas are distributed more or less evenly, and so are the leaders. When all nodes are up, a query acts in a very similar manner to what occurs in a three node cluster. Reads are routed to lease holders, which route their answers back to the gateway, and from there to the client. Writes are similar but go through a distributed consensus before sending back acknowledgement. When a node goes down, the situation is also very similar to the three-node case, or it will be initially. As before, ranges with a lost leader will elect new ones within seconds. The cluster will remain available for reads and writes but it'll be in a fragile state. Now with the three node situation, the cluster had to remain in that fragile state indefinitely, until it could get a third node. Because prior to that, only two nodes were up and both already had replicas of every range. Here, we still have more than three nodes up and some of them don't have replicas from lost ranges. But they could. In a few minutes, five minutes by default, the cluster will stop waiting for that lost node to return and declare it dead. When that happens, the cluster will heal itself by up-replicating the under-replicated ranges to other nodes that don't yet have them. That node might be dead, but new replicas are put on the other nodes with each starting out by taking a consistent snapshot of the range before becoming a follower. At that point, the cluster has actually healed itself. All ranges are again fully replicated in spite of the lost node. The cluster is actually once again resilient and could tolerate another node failure without loss of availability.
Geo Replication
We already said that the database should be distributed, but in many cases, there are legal restrictions that require data to never leave a certain region. That's where geo-replication steps in. It is a general term for the ability to control where your data resides in a globally distributed cluster to that requirement. Even if there are no legal concerns, you still shouldn't need to send a query halfway around the world when some of your nodes are sitting in a data center one city over. CockroachDB delivers this with its features that allow users to peg data to a particular locality. Additionally, a true distributed SQL database should be multi-cloud, meaning it shouldn't be tied to a specific cloud provider. Spanner might be a basic distributed SQL database, but if you use it, you're locked into Google Cloud. Your database should be able to run anywhere on any combination of bare metal servers or cloud instances for multiple providers and to do so seamlessly. CockroachDB doesn't care where it's running. A node is a node, and any node that joins a cluster will work.


Comments
Post a Comment